Shaw TalebiFine-Tuning Text Embeddings For Domain-Specific SearchAn overview with Python codeJan 244Jan 244
InGenerative AIbyKaushik RajanCOCONUT: Redefining Reasoning in Large Language ModelsRevolutionizing reasoning in large language models through latent space.Dec 17, 20248Dec 17, 20248
InCausality in Data SciencebyKenneth StyppaIntroducing Causal Feature LearningCausal Feature Learning Pt. 1Oct 22, 20241Oct 22, 20241
SACHIN KUMARKV Cache compression with Inter-Layer Attention Similarity for efficient Long-Context LLM InferenceFor longer context LLM Inference, existing methods, including selective token retention and window-based attention, improve efficiency but…Dec 4, 2024Dec 4, 2024
SACHIN KUMARMCT Self-Refine algorithm : integrating LLMs with Monte Carlo Tree Search for complex mathematical…LLMs faces challenges in accuracy and reliability in strategic and mathematical reasoning. For addressing it, authors of this paper[1]…Jun 17, 2024Jun 17, 2024
Ozgur GulerThe Missing Piece in Graph RAG: Graph Attention NetworksHow Enhanced Contextual Relevance with GNN’s can improve GraphRAGNov 21, 20243Nov 21, 20243
InTDS ArchivebyBenjamin WangMonte Carlo Tree Search: An IntroductionMCTS is the cornerstone of AlphaGo and many AI applications. We aim to build some intuitions and along the way get our hands dirty.Jan 10, 20212Jan 10, 20212
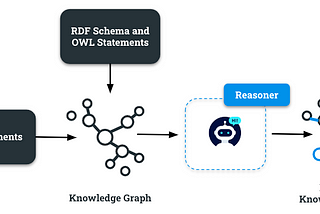
InTDS ArchivebyGiuseppe FutiaOntology Reasoning in Knowledge GraphsA Python hands-on guide to understanding the principles of generating new knowledge by following logical processesNov 15, 20245Nov 15, 20245
InTDS ArchivebyTomaz BratanicBuilding Knowledge Graphs with LLM Graph TransformerA deep dive into LangChain’s implementation of graph construction with LLMsNov 5, 202414Nov 5, 202414
Pierre LienhartLLM Inference Series: 1. IntroductionIn this post, I introduce the outline of this deep dive series about the specifics and challenges of hosting LLMs for inference.Dec 22, 20231Dec 22, 20231
SACHIN KUMARvAttention: Dynamic KV-cache Memory Management for Serving LLMs without PagedAttentionEfficient GPU memory usage is essential for high throughput LLM inference. Prior systems reserved memory for the KV-cache ahead-of-time…May 9, 20243May 9, 20243
InTDS ArchivebyElahe AghapourBeyond Attention: How Advanced Positional Embedding Methods Improve upon the Original TransformersFrom Sinusoidal to RoPE and ALiBi: How advanced positional encodings overcome limitations in TransformersOct 29, 20241Oct 29, 20241
InTDS ArchivebyBenjamin BodnerPyTorch Optimizers Aren’t Fast Enough. Try These InsteadThese 4 advanced optimizers will open your mind.Oct 14, 20249Oct 14, 20249
Emergent MethodsOutperforming Claude 3.5 Sonnet with Phi-3-mini-4k for graph entity relationship extraction tasksWhen you need fast and high-throughput graph extraction with better quality than Claude 3.5 Sonnet.Aug 15, 20244Aug 15, 20244
InNeo4j Developer BlogbyTomaz BratanicEntity Linking and Relationship Extraction With Relik in LlamaIndexBuild a knowledge graph without an LLM for your RAG applicationsAug 12, 20247Aug 12, 20247
InNeo4j Developer BlogbyTomaz BratanicBuild a Knowledge Graph-based Agent With Llama 3.1, NVIDIA NIM, and LangChainFunction-calling capabilities retrieve structured data from a knowledge graph to power your RAG appsAug 3, 20241Aug 3, 20241
InMantisNLPbyJuan MartinezFinetuning an LLM: RLHF and alternatives (Part I)IntroductionAug 16, 2023Aug 16, 2023
Amandeep SinghHow make async calls to OpenAI’s API.A guide to make asynchronous calls to OpenAI API with rate limiting.Feb 25, 20241Feb 25, 20241
Jeong YitaeToday, I’d like to discuss the evaluation methods for GraphRAG.Additionally, there are evaluation methods where LLMs serve as the evaluators, including single point, reference-based, and pairwise-based…Jul 3, 20241Jul 3, 20241
InPalantir BlogbyPalantirIndustry AIHow Palantir AIP Enables the Unified NamespaceJun 27, 20242Jun 27, 20242